
Twitter Spam Bot Classifier
Spam-bot classification of tweets using NLP extracted features and meta-features with traditional machine learning and deep learning
Tags: python, scikit-learn, tensorflow, tf-idf, w2v, NLP
By Carlos Huerta on Aug 23 2020
Summary
BotDetector3000 was the capstone project for RuG's 2019 machine-learning course. I worked alongside Panagiotis Giagkoulas to develop a twitter spam-bot classifier that uses both; extracted NLP features and tweet metadata to detect whether or not a particular tweet was written by either a bot or a human. Training data was taken from the cresci-2017 dataset available here.
Motivation
Who hasn't eagerly opened their twitter homepage clicked on the most recent trend to get informed to find out that it is someone trying to sell you something, or worse it is a blatant scam targeted at the most naive users. I am sure most of you guys sure remember a certain Nigerian prince with a vast fortune wanting your help? This and the recent rise of fake-news trends, motivated us to develop a machine learning model that would help us to distinguish real human to human interaction across social media, in our specific case it was targeted at twitter.
Challenges
Twitter has a lot of available data; the main issue is that most of it is unlabeled and unstructured. We solved this by using Indiana's University Network and Science Institute bot repository which hosts many datasets of tweets of previously verified human accounts and identified (and now suspended) bot-accounts. Nevertheless, both human and bot tweets are especially problematic when it comes to NLP feature extraction. One example of this, you would think that a normal person would write:
Oh what a lovely day, the weather has been fantastic this week.
But no! Normally tweets are most similar to:
Oh gr8 😀 here comez da sun 🌞 🕶️ #week#sunlight
Now, normally when you do NLP feature extraction, it is a common practice to tokenize and stem your documents to get a vector representation that can be fed into our models. Now let's see what tokenization + stemming does to the first 'correctly written text'. First, we remove stop-words:
lovely day weather fantastic week
Now applying NLTK's Snowball stemmer:
love day weather fantast week
Our document has not lost its meaning and retains much of the important information that contained the original text. Therefore we can proceed without any issues to tokenize and transform into vector form the new document.
Now we will do the same thing to our tweet.
Stop word removal:
gr8 comez da sun #week#sunlight
Snowball stemmer:
gr8 comez da sun # week # sunlight
As you can see, it did not change so much form the original tweet, so information extracted from this particular document will not be very useful for our model. 😞
Model Pipe-Line
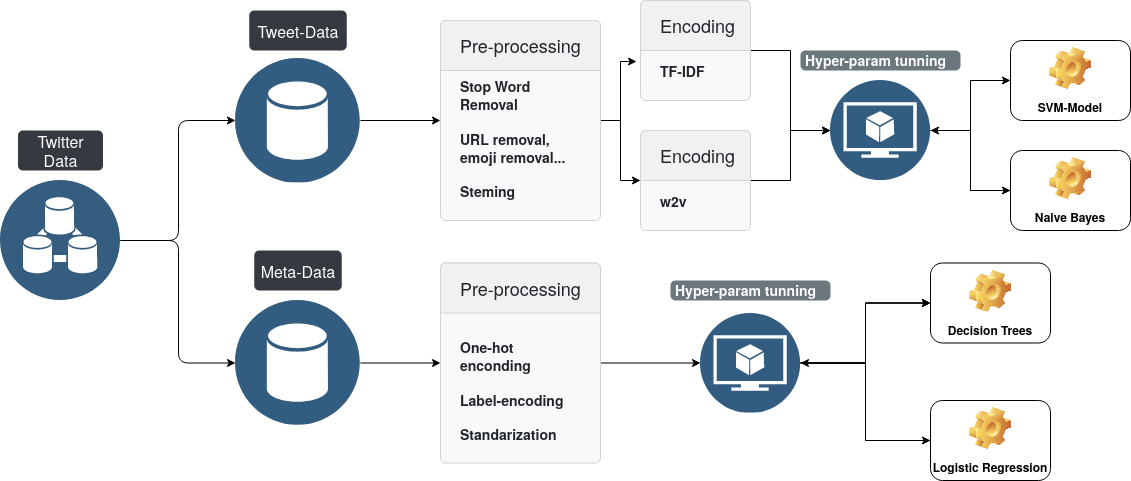
Solutions
A lot of pre-processing was necessary to remove most of the slang, emojis, hashtags, URL's, poorly written tweets, most of the time of the project was spent on data cleaning and pre-processing. We managed to implement a pretty good tweet 'cleanser' that would transform
Oh gr8 😀 here comez da sun 🌞 🕶️ #week#sunlight
Into:
here com sun week sunlight
Which still losses some information, but it was sufficient enough for our models. Afterwards, we used a term frequency-inverse document frequency (tf-idf) as a baseline vector representation of the cleansed tweets and then we moved into a word to vector (w2v) model to encode a more sophisticated language model. Then we ran multiple experiments using traditional ml-methods like support vector machines, logistic regression and decision trees to get the most accurate result.
Results
Our pure NLP model achieved a maximum of 84% accuracy on the test set after hyperparameter tunning; it used custom 200 dimensions word embedding and an SVM with an RBF kernel. The meta-data focused model achieved a whopping 87% accuracy on the test set! Proving that sometimes meta-data is as useful as (or better) as the data itself.
FUN FACTS: Bots tend to write better english than most humans :D and they really love their URL's
- Want to know more? Leave a comment and I will share to you the full final report.
- Want to see the code? It is open-source and available at GH.